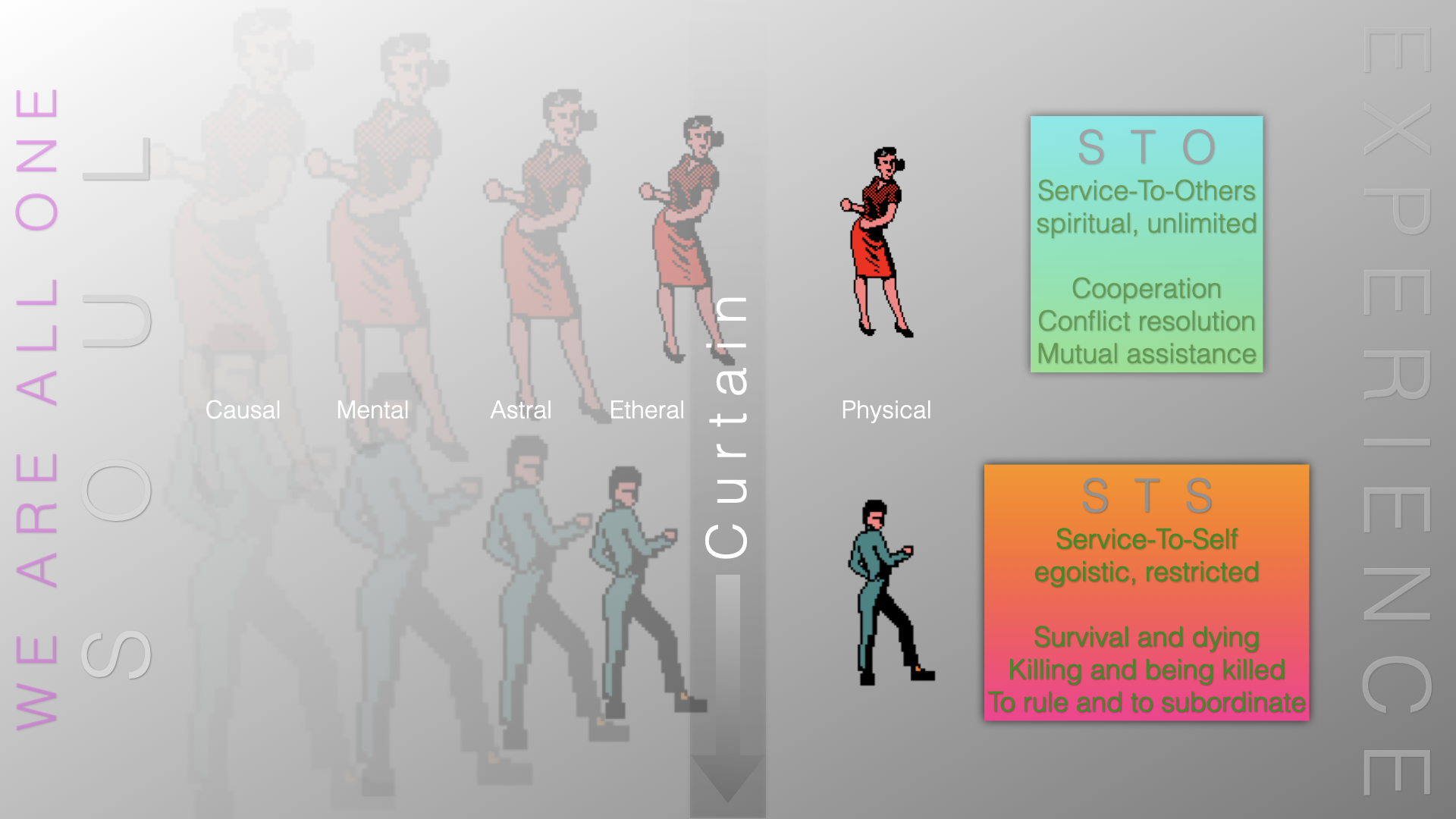
Unlimited Information Flow